How to Monitor DNS Resolution Latency
DNS latency happens before your app logs a single request. Learn how Anycast routing fails and how to measure true P99 lookup times from the edge.

Engineering teams pour massive resources into shaving 50 milliseconds off their Time-To-First-Byte (TTFB). They implement caching layers, edge compute, and CDN edge-routing. Yet, they consistently ignore the very first step of every TLS handshake: resolving the hostname.
The Anycast Illusion
Modern DNS is powered by Anycast routing. Instead of a single server holding your records, your DNS provider broadcasts the same IP address from hundreds of data centers globally. The Border Gateway Protocol (BGP) naturally routes a user's query to the physically closest nameserver.
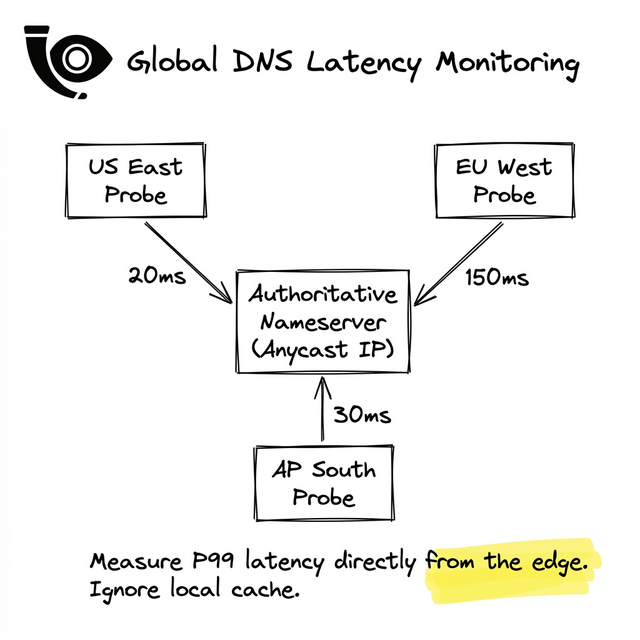
Most of the time, this works beautifully. But BGP doesn't route based on fiber-optic distance; it routes based on network hops. If a major peering link drops in Miami, BGP might silently route the entire Florida peninsula's DNS queries to a nameserver in São Paulo, adding 150ms of invisible latency to every single new connection.
Uncovering Invisible Latency
Because DNS latency occurs before an HTTP connection is established, it will never appear in your backend logs. The only way to detect a regional Anycast routing failure is to actively measure it from the outside.
You can test the raw authoritative response time using a simple curl command against a DNS-over-HTTPS (DoH) endpoint:
curl -s -w "Total: %{time_total}s\n" "https://cloudflare-dns.com/dns-query?name=yourdomain.com"However, doing this manually only proves latency from your specific location.
Measuring the Global P99
The only effective monitoring strategy for DNS latency is global, continuous, synthetic probing. You must measure the P99 resolution time from endpoints spanning North America, Europe, Asia, and South America simultaneously.
Conclusion
You cannot optimize what you cannot measure. DNS latency degrades user experience before your application is even aware a user exists.
By implementing Heimdall Observer, you benefit from a distributed network of probes that constantly analyze Anycast routing health, instantly alerting your on-call team if your DNS provider experiences a regional peering degradation.
Senior Systems Reliability Engineer focused on uptime, incident response, and building monitoring systems that surface problems before users notice.
"We built Heimdall Observer to monitor the kinds of issues discussed in this article."