Complete Guide to DNS Monitoring: Prevent Downtime and Detect Failures
DNS failures are a massive blind spot for most SRE teams. Learn the failure modes, debugging workflows, and monitoring strategies to prevent silent downtime.

When an application goes offline, engineering teams rush to their APM dashboards. They check CPU charts, database connection pools, and application logs. Often, they find nothing wrong at all. The servers are perfectly healthy, yet customers are flooding support with 'site unreachable' messages.
The Silent Dependency: Why Your Uptime Metrics Lie
This phenomenon—often dubbed 'inside-out blindness'—happens because your internal probes don't traverse the same path as your users. They are completely blind to the internet's most critical, and most fragile, routing layer: the Domain Name System.
Because DNS operates as a massive, globally distributed, eventually-consistent database, a failure in the resolution chain won't register as a 500 Internal Server Error. It registers as total silence.
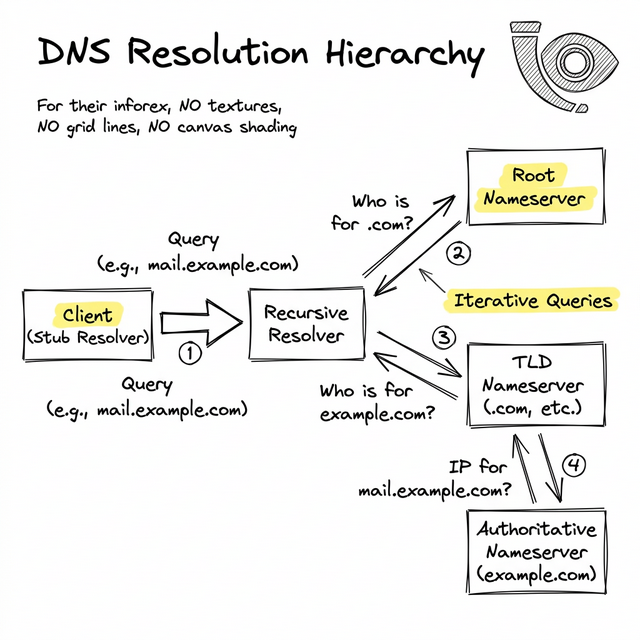
As illustrated, the resolution journey introduces several external dependencies before a TCP handshake can even begin:
- Client-side stub resolvers (which cache aggressively)
- Recursive resolvers run by the ISP (e.g., Comcast, Vodafone)
- The internet's Root and Top-Level Domain (TLD) infrastructure
- Your configured authoritative nameservers
Where the Chain Breaks
While catastrophic outages at the Root level are exceptionally rare, the edges of this network fail constantly. The most common disruptions originate from misconfigurations or cascading timeouts:
- Stale Cache Traps
During a rapid infrastructure migration, if your previous IP addresses had a Time-To-Live (TTL) of 24 hours, the majority of the internet will refuse to query your new nameservers until that timers elapses, effectively stranding your users on offline hardware.
- Split-Brain Records
If you operate multiple authoritative, redundant nameservers, an incomplete zone synchronization can cause intermittent failures. A user in Tokyo might receive the correct IP, while a user in London hits a nameserver serving a stale version of the zone file.
SRE Triage Playbook
When investigating a suspected DNS drop, you must ignore your browser cache and query the source of truth. Rather than a standard 'dig', you can specifically verify the serial numbers across your nameservers to detect split-brain synchronization issues:
host -t SOA yourdomain.com ns1.yourprovider.com host -t SOA yourdomain.com ns2.yourprovider.com
If the serial numbers returned do not perfectly match, your nameservers are out of sync and serving different realities to different geographic regions.
Designing a Mature Observability Posture
Replacing ping-based uptime checks with comprehensive external monitoring is mandatory for production workloads.
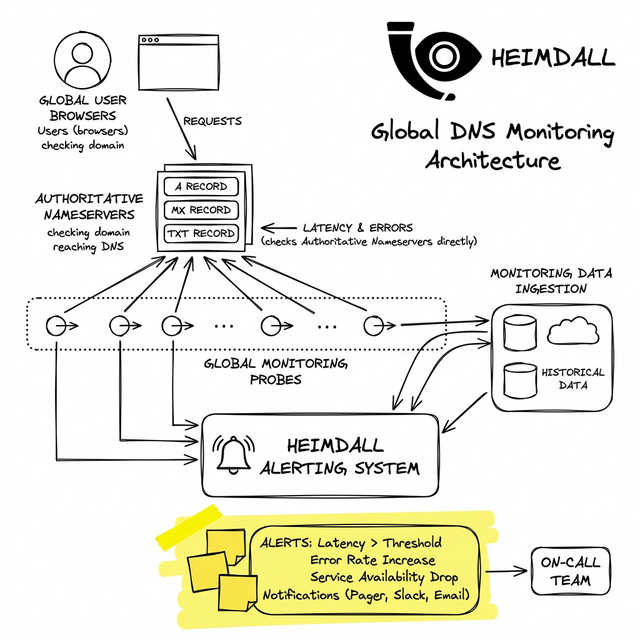
A robust posture requires testing the resolution path from the outside-in. Your monitoring probes must:
- Execute raw, non-cached queries from multiple geographic POPs.
- Validate that the returned IP addresses strictly match your expected ASN.
- Alert on P99 resolution latency—because slow DNS is indistinguishable from a slow backend.
Related Deep Dives
Explore our series on engineering and scaling DNS reliability:
- How DNS Failures Cause Invisible Downtime
- How to Debug DNS Resolution Problems Like an SRE
- DNS Propagation Explained: Why Changes Take Hours
- What Causes SERVFAIL Errors in DNS
- DNS TTL Best Practices for Production Systems
- How to Monitor DNS Resolution Latency
- Best DNS Monitoring Tools for Infrastructure Teams
- How to Fix DNS SERVFAIL Errors
Final Thoughts
Operational resilience isn't just about auto-scaling compute; it's about ensuring your customers can reliably reach that compute. We designed
Heimdall Observer to bridge this exact visibility gap. By querying your authoritative endpoints from a global vantage network, Heimdall provides real-time alerts on latency drift, SERVFAIL spikes, and record mismatches before they spiral into customer-facing incidents.
Ingeniero sénior de confiabilidad de sistemas (SRE) enfocado en la disponibilidad, respuesta a incidentes y construcción de sistemas de monitoreo que revelen problemas antes de que los usuarios lo noten.
"Creamos Heimdall Observer para monitorizar los tipos de problemas que se tratan en este artículo."