DNS TTL Best Practices for Production Systems
Setting a DNS TTL too high can cause 24-hour outages, while setting it too low can DDoS your nameservers. Learn the best practices for production TTL management.

Time-To-Live (TTL) is the engine of internet caching. It is a single integer that dictates the balance between agility and resilience. Set it too high, and a simple migration becomes a multi-day ordeal. Set it too low, and you risk overwhelming your DNS provider with queries.
The Agility vs. Resilience Tradeoff
When you publish an A record with a TTL of 3600 seconds, you are telling every ISP in the world: 'Do not ask me for this record again for an hour.' This provides massive resilience. If your DNS provider suffers a total outage 5 minutes later, your users won't notice, because their ISP already has the answer.
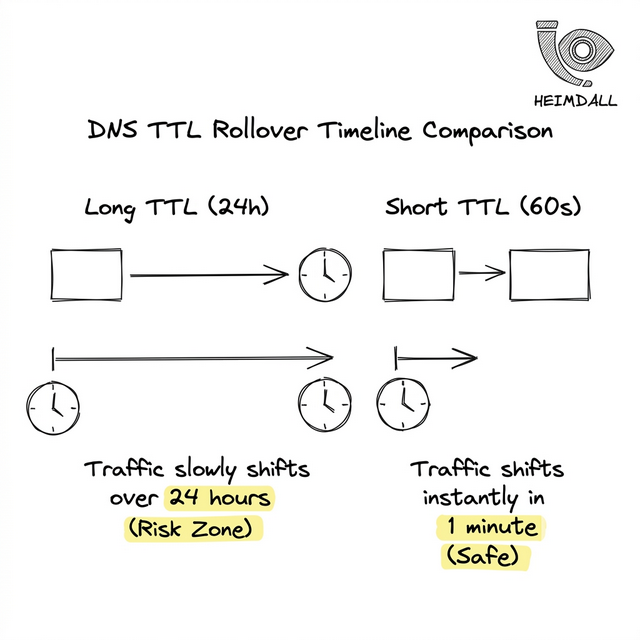
But resilience trades off against agility. If your primary load balancer dies and you update your DNS to point to a backup, that 1-hour TTL means traffic will continue flowing to the dead load balancer until the local caches expire.
The CDN Override Reality
A common misconception is that you control your TTL globally. In reality, large recursive resolvers (like some mobile carriers) will enforce their own minimum TTLs to save bandwidth. More importantly, Content Delivery Networks (CDNs) often override your authoritative TTL entirely for proxied records, relying on their own edge logic.
Best Practices for SREs
Operating DNS in production requires a tiered approach to TTLs:
- Static Infrastructure (MX, TXT): Use 86400 (24 hours). These rarely change, and high TTLs protect your email delivery against DNS provider outages.
- Dynamic Endpoints (A, AAAA, CNAME): Use 300 (5 minutes). This provides a tight window for failover scripts to redirect traffic during an incident.
- Migration Windows: 48 hours before tearing down old infrastructure, lower the dynamic TTL to 60 seconds. Wait. Perform the migration. Raise it back to 300 seconds.
Conclusion
TTL management is the foundation of zero-downtime routing.
With Heimdall Observer, you can audit the TTL of your critical records to ensure they haven't been accidentally hardcoded to a high value, preventing a catastrophic lockout during your next incident.
Ingeniero sénior de confiabilidad de sistemas (SRE) enfocado en la disponibilidad, respuesta a incidentes y construcción de sistemas de monitoreo que revelen problemas antes de que los usuarios lo noten.
"Creamos Heimdall Observer para monitorizar los tipos de problemas que se tratan en este artículo."