Las fallas de DNS son un punto ciego masivo para los equipos de SRE. Aprenda los modos de falla, flujos de trabajo de depuración y estrategias de monitoreo para prevenir caídas silenciosas.

Cuando una aplicación se desconecta, los equipos de ingeniería corren a sus paneles de APM. Verifican los gráficos de CPU, los grupos de conexiones de bases de datos y los registros de la aplicación. A menudo, no encuentran nada malo. Los servidores están perfectamente sanos y, sin embargo, los clientes inundan el soporte con mensajes de 'sitio inalcanzable'.
Este fenómeno —a menudo denominado 'cegueira de adentro hacia afuera'— ocurre porque sus sondas internas no recorren el mismo camino que sus usuarios. Son completamente ciegas a la capa de enrutamiento más crítica y frágile de Internet: el Sistema de Nombres de Dominio (DNS).
Debido a que el DNS funciona como una base de datos masiva, distribuida globalmente y eventualmente consistente, una falla en la cadena de resolución no se registrará como un Error Interno del Servidor 500. Se registrará como un silencio total.
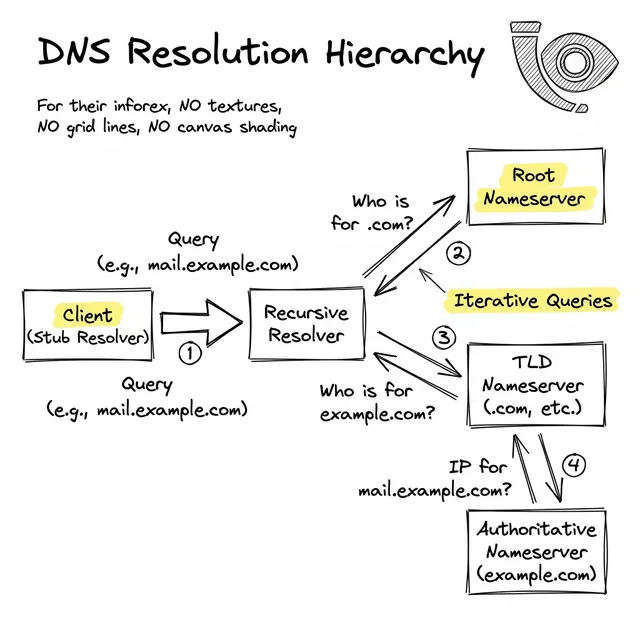
Como se ilustra, el viaje de resolución introduce varias dependencias externas antes de que pueda comenzar un apretón de manos TCP:
Si bien las interrupciones catastróficas a nivel de Raíz son excepcionalmente raras, los bordes de esta red fallan constantemente. Las interrupciones más comunes se originan por configuraciones erróneas o tiempos de espera en cascada:
Durante una migración rápida de infraestructura, si sus direcciones IP anteriores tenían un Time-To-Live (TTL) de 24 horas, la mayoría de Internet se negará a consultar sus nuevos servidores de nombres hasta que transcurra ese temporizador.
Si opera múltiples servidores de nombres autoritativos y redundantes, una sincronización de zona incompleta puede causar fallas intermitentes. Un usuario en Tokio podría recibir la IP correcta, mientras que uno en Londres golpea un servidor que sirve una versión antigua.
Reemplazar las comprobaciones de tiempo de actividad basadas en ping con un monitoreo externo integral es obligatorio para las cargas de trabajo de producción.
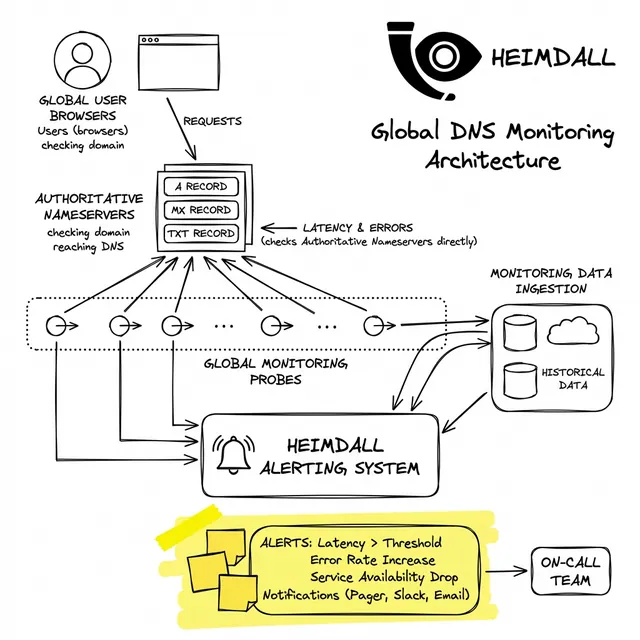
Una postura robusta requiere probar la ruta de resolución desde afuera hacia adentro. Sus sondas de monitoreo deben:
La resiliencia operativa no se trata solo de escalar automáticamente el cómputo; se trata de garantizar que sus clientes puedan alcanzar ese cómputo de manera confiable. Diseñamos Heimdall Observer para cerrar esta brecha de visibilidad.
Heimdall Observer fue construido para proteger su infraestructura digital. Comience hoy con alertas en tiempo real, análisis detallados y monitoreo confiable.
Comienza Gratis
Ingeniero sénior de confiabilidad de sistemas (SRE) enfocado en la disponibilidad, respuesta a incidentes y construcción de sistemas de monitoreo que revelen problemas antes de que los usuarios lo noten.


