Les pannes DNS sont un angle mort massif pour les équipes SRE. Apprenez les modes de défaillance, les workflows de débogage et les stratégies de surveillance pour prévenir les pannes silencieuses.

Lorsqu'une application se déconnecte, les équipes d'ingénierie se précipitent sur leurs tableaux de bord APM. Elles vérifient les graphiques du processeur, les pools de connexions de bases de données et les journaux d'application. Souvent, elles ne trouvent rien d'anormal. Les serveurs sont en parfaite santé, et pourtant les clients inondent le support de messages 'site inaccessible'.
Ce phénomène – souvent appelé 'cécité de l'intérieur vers l'extérieur' – se produit parce que vos sondes internes ne parcourent pas le même chemin que vos utilisateurs. Elles sont complètement aveugles à la couche de routage la plus critique et la plus fragile d'Internet : le Système de Noms de Domaine (DNS).
Parce que le DNS fonctionne comme une base de données massive, répartie mondialement et éventuellement cohérente, une panne dans la chaîne de résolution ne s'enregistrera pas comme une Erreur Interne du Serveur 500. Elle s'enregistrera comme un silence total.
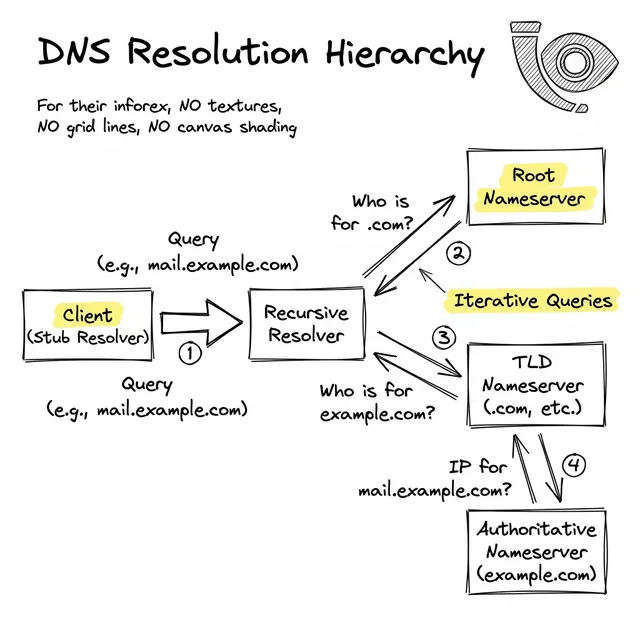
Comme illustré, le voyage de résolution introduit plusieurs dépendances externes avant qu'une négociation TCP ne puisse même commencer :
Bien que les pannes catastrophiques au niveau Racine soient exceptionnellement rares, les bords de ce réseau échouent constamment. Les interruptions plus courantes proviennent de mauvaises configurations ou de délais d'expiration en cascade :
Lors d'une migration rapide d'infrastructure, si vos anciennes adresses IP avaient une Time-To-Live (TTL) de 24 heures, la majorité d'Internet refusera d'interroger vos nouveaux serveurs avant l'expiration de ce minuteur.
Si vous gérez plusieurs serveurs de noms faisant autorité et redondants, une synchronisation de zone incomplète peut provoquer des pannes intermittentes. Un utilisateur à Tokyo pourrait recevoir l'IP correcte, tandis qu'un utilisateur à Londres frappe un serveur servant une version périmée.
Remplacer les vérifications de disponibilité basées sur le ping par une surveillance externe complète est obligatoire pour les charges de travail de production.
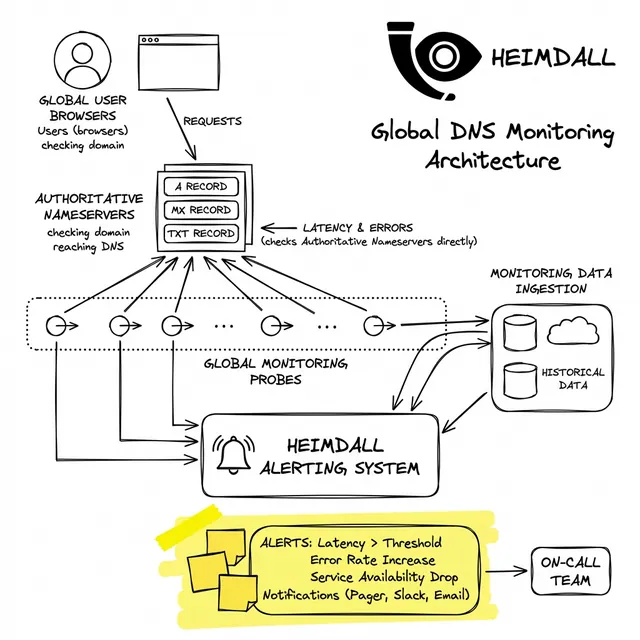
Une posture robuste exige de tester le chemin de résolution de l'extérieur vers l'intérieur. Vos sondes de surveillance doivent :
La résilience opérationnelle ne concerne pas seulement l'auto-scaling du calcul ; il s'agit de garantir que vos clients peuvent atteindre ce calcul de manière fiable. Nous avons conçu Heimdall Observer pour combler exactement cet écart de visibilité.
Rejoignez des milliers d'équipes qui comptent sur Heimdall pour maintenir leurs sites web et API en ligne 24h/24 et 7j/7. Commencez avec notre plan gratuit dès aujourd'hui.
Commencer la surveillance gratuitement
Ingénieur senior en fiabilité des systèmes (SRE) axé sur la disponibilité, la réponse aux incidents et la construction de systèmes de surveillance qui révèlent les problèmes avant que les utilisateurs ne s'en aperçoivent.


