Best DNS Monitoring Tools for Infrastructure Teams
Stop trusting internal metrics for external outages. Learn the architectural principles of outside-in DNS synthetic monitoring for SRE teams.

When evaluating observability platforms, engineering teams often prioritize APM tracing, log aggregation, and internal metric cardinality. But if you rely on those tools to monitor DNS, you are fundamentally configuring them to lie to you.
The Trust Boundary Problem
A Datadog agent running on an EC2 instance operates inside a highly privileged VPC. When it pings an API endpoint, it uses a private, cloud-level DNS resolver. Because this internal network bypasses the public internet completely, your agent will report 100% uptime while the actual public nameservers are offline.
To monitor external dependencies, your tools must live outside your trust boundary.
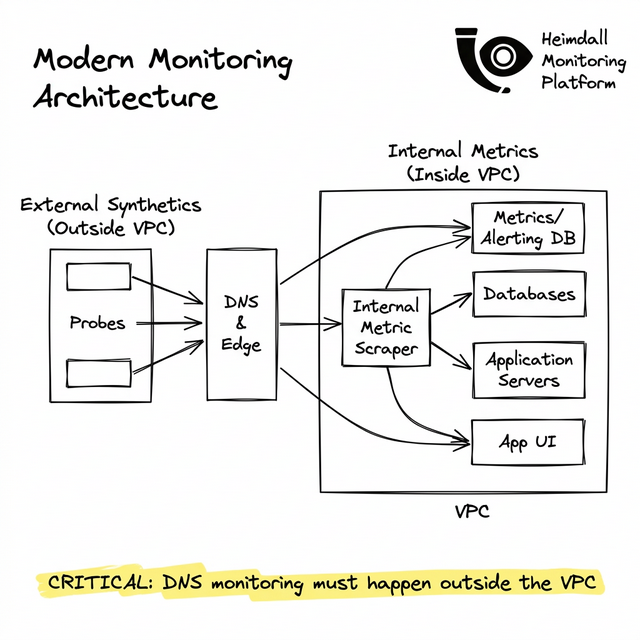
The Anatomy of Outside-In Monitoring
A dedicated DNS monitoring tool must provide 'Synthetic' testing: deploying lightweight, stateless execution environments (probes) across multiple global ISPs to run raw DNS queries exactly as a user would.
A production-grade tool must track:
- Authoritative Response Latency (P99)
- SOA Serial Number consistency across redundant nameservers
- A/AAAA record payload verification against an expected whitelist
The Three-Region Rule
Because the internet is noisy, a single synthetic probe in Frankfurt failing to resolve your domain does not constitute a Sev-1 incident; it usually indicates a localized BGP flap. The best tools enforce a 'Three-Region Rule': PagerDuty is only triggered if probes in at least three distinct geographic regions report an authoritative failure simultaneously.
Conclusion
Trusting an internal metrics dashboard during a DNS outage is like trusting a fuel gauge on a car with no wheels.
Platforms natively designed for the edge, like Heimdall Observer, sit entirely outside your cloud provider's walled garden. They provide the global, dedicated synthetic monitoring necessary to detect public resolution failures before your customers ever hit a timeout.
Ingénieur senior en fiabilité des systèmes (SRE) axé sur la disponibilité, la réponse aux incidents et la construction de systèmes de surveillance qui révèlent les problèmes avant que les utilisateurs ne s'en aperçoivent.
"Nous avons conçu Heimdall Observer pour surveiller les types de problèmes abordés dans cet article."