DNS Propagation Explained: Why Changes Take Hours
DNS propagation isn't about data syncing—it's about cache expiration. Learn how TTLs work and how to execute zero-downtime DNS migrations.

There is a persistent myth that updating a DNS record requires waiting for servers around the globe to 'synchronize' the new data, like pouring water into a complex pipe system. This is fundamentally untrue.
DNS propagation is not about pushing new data out into the world. It is strictly a waiting game. It is the mathematical certainty of waiting for old data to expire from millions of independent caches.
The Math of Time-to-Live (TTL)
Every DNS record you publish contains a TTL integer, measured in seconds. When an internet service provider's recursive resolver queries your domain, it looks at that TTL. If the TTL is 86400 (24 hours), the resolver makes a promise: it will not ask your servers for an update for the next 86,400 seconds.
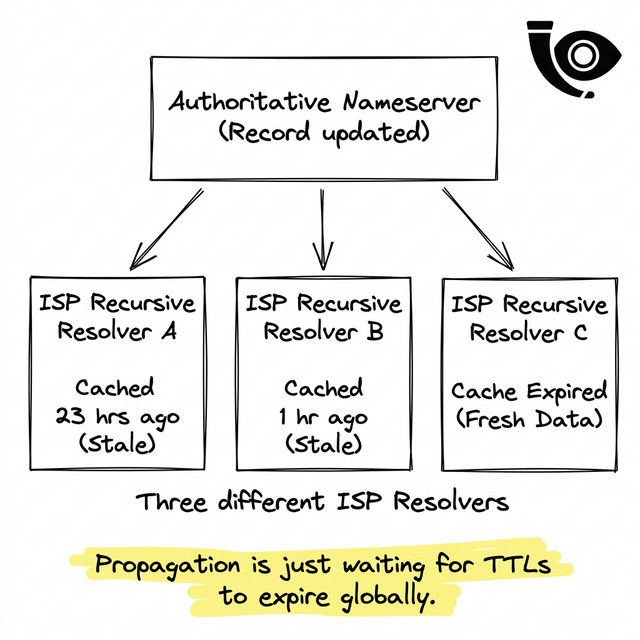
If you change your IP address five minutes after that resolver cached your record, your new IP is completely invisible to every customer using that specific ISP until tomorrow.
Visualizing the Ticking Clock
You can visualize this expiration process from a public resolver. By parsing a command-line query, you can watch the exact seconds tick down until the cache clears:
dig +noall +answer @8.8.8.8 example.com
The second column in the output will show a number steadily decreasing on sequential runs. Once it hits zero, the very next request will finally reach your authoritative nameserver and retrieve your updated IP.
The Zero-Downtime Migration Playbook
SRE teams conduct flawless migrations by manipulating this TTL math. If you plan to switch load balancers on a Saturday night:
- Thursday night: Lower your TTL from 86400 to 60 seconds.
- Friday: Wait the full 24 hours. The internet is slowly forgetting your old long-term cache limit.
- Saturday night: Perform the migration. Because the TTL is now 60 seconds globally, propagation takes exactly one minute.
- Sunday morning: Raise the TTL back to 86400 to improve CDN routing performance and reduce load on your DNS provider.
When Things Go Wrong
Occasionally, rogue ISPs will hardcode minimum TTLs (refusing to honor anything under 1 hour) to save on bandwidth costs. In these edge cases, small pockets of users will remain stranded on your old infrastructure longer than expected, which is why preserving legacy routing until traffic completely zero-lines is a critical safety margin.
Conclusion
DNS propagation is entirely predictable if you understand caching mechanics.
By heavily instrumenting your infrastructure with Heimdall Observer, you can track record drift across authoritative servers to guarantee your updates were published correctly, allowing you to confidently predict when global traffic will naturally shift to your new targets.
Engenheiro de infraestrutura focado em DNS, redes e nas camadas invisíveis que determinan se as aplicações são alcançáveis.
"Criamos o Heimdall Observer para solucionar os problemas discutidos neste artigo."