DNS-Fehler sind ein massiver blinder Fleck für SRE-Teams. Lernen Sie Fehlermodi, Debugging-Workflows und Überwachungsstrategien kennen, um stille Ausfälle zu verhindern.

Wenn eine Anwendung offline geht, stürzen sich die Engineering-Teams auf ihre APM-Dashboards. Sie überprüfen CPU-Diagramme, Datenbankverbindungspools und Anwendungsprotokolle. Oft finden sie überhaupt nichts Falsches. Die Server sind vollkommen gesund, und dennoch überschwemmen Kunden den Support mit 'Seite nicht erreichbar'-Nachrichten.
Dieses Phänomen – oft als 'Inside-Out-Blindheit' bezeichnet – tritt auf, weil Ihre internen Sonden nicht denselben Pfad zurücklegen wie Ihre Nutzer. Sie sind völlig blind für die kritischste und fragilste Routing-Schicht des Internets: das Domain Name System (DNS).
Da das DNS als eine massive, global verteilte, eventuell konsistente Datenbank fungiert, wird ein Fehler in der Auflösungskette nicht als 500 Internal Server Error registriert. Er wird als absolute Stille registriert.
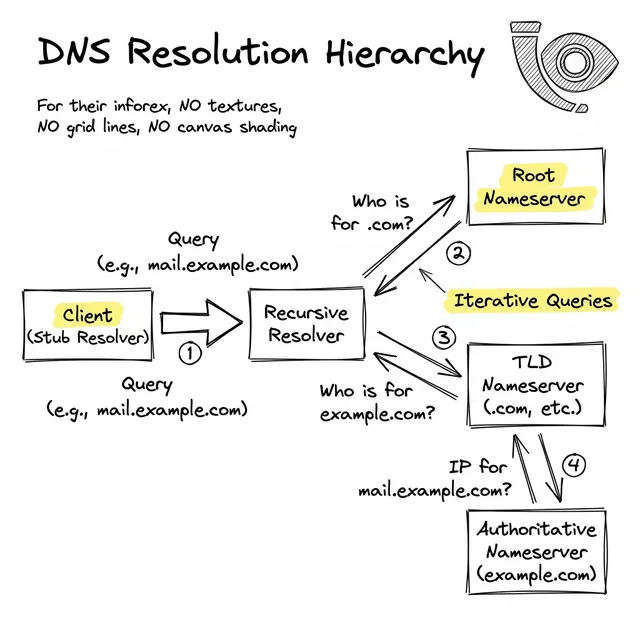
Wie illustriert, führt der Auflösungspfad mehrere externe Abhängigkeiten ein, bevor überhaupt ein TCP-Handshake beginnen kann:
Während katastrophale Ausfälle auf Root-Ebene äußerst selten sind, fallen die Ränder dieses Netzwerks ständig aus. Die häufigsten Störungen resultieren aus Fehlkonfigurationen oder kaskadierenden Timeouts:
Wenn bei einer schnellen Infrastrukturmigration Ihre alten IP-Adressen eine Time-To-Live (TTL) von 24 Stunden hatten, wird sich der Großteil des Internets weigern, Ihre neuen Nameserver abzufragen, bis dieser Timer abläuft.
Wenn Sie mehrere autoritative, redundante Nameserver betreiben, kann eine unvollständige Zonensynchronisation zu intermittierenden Fehlern führen. Ein Nutzer in Tokio erhält möglicherweise die korrekte IP, während ein Nutzer in London auf einen Server trifft, der eine veraltete Version der Zonendatei bedient.
Wenn Sie einen vermuteten DNS-Ausfall untersuchen, müssen Sie Ihren Browser-Cache ignorieren und die 'Source of Truth' abfragen. Anstatt eines Standard-'dig' können Sie die Seriennummern auf Ihren Nameservern überprüfen, um Split-Brain-Probleme zu erkennen:
host -t SOA ihre-domain.com ns1.ihr-provider.com host -t SOA ihre-domain.com ns2.ihr-provider.com
Wenn die zurückgegebenen Seriennummern nicht perfekt übereinstimmen, sind Ihre Nameserver nicht synchron und bedienen unterschiedliche Realitäten für unterschiedliche Regionen.
Das Ersetzen von Ping-basierten Uptime-Checks durch umfassendes externes Monitoring ist für Produktions-Workloads zwingend erforderlich.
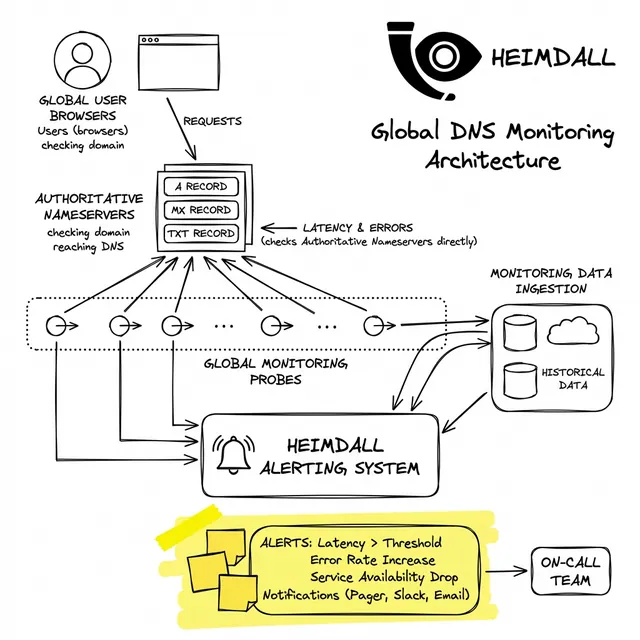
Eine robuste Haltung erfordert das Testen des Auflösungspfads von außen nach innen. Ihre Überwachungssonden müssen:
Betriebliche Resilienz bedeutet nicht nur das automatische Skalieren von Rechenleistung; es geht darum, sicherzustellen, dass Ihre Kunden diese Rechenleistung zuverlässig erreichen können. Wir haben Heimdall Observer entwickelt, um genau diese Sichtbarkeitslücke zu schließen.
Schließen Sie sich Tausenden von Teams an, die sich darauf verlassen, dass Heimdall ihre Websites und APIs rund um die Uhr online hält. Starten Sie noch heute mit unserem kostenlosen Plan.
Kostenlos mit der Überwachung beginnen
Senior Systems Reliability Engineer focused on uptime, incident response, and building monitoring systems that surface problems before users notice.


