A comprehensive guide to TLS lifecycles, common expiration failures, and how to implement robust synthetic monitoring to catch certificate issues.

Modern infrastructure relies entirely on cryptographic trust to secure communications. Yet, despite infinite budgets and sophisticated APM tooling, major platforms continue to suffer devastating outages for a profoundly simple reason: someone forgot to renew a file.
The fragility of the TLS lifecycle means that when certificates fail, they fail hard. There is no graceful degradation in cryptography. If a certificate expires, or a trust chain breaks, the application goes instantly offline for all clients.
To understand how to monitor certificates, we must first look at how the TLS handshake validates trust. When a client connects to your edge router, it performs cryptographic handshakes demanding two things:
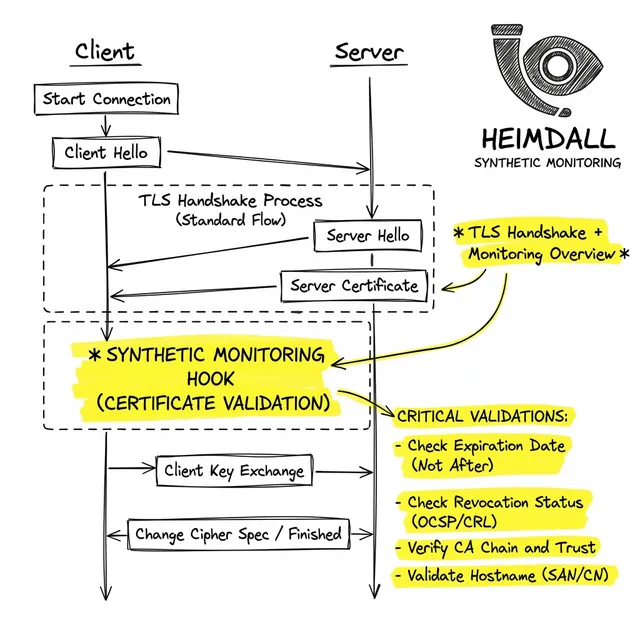
In practice, this usually fails because internal health checks only verify that a process is running, not that the public-facing endpoint presents valid cryptography. The most common failures are:
An operations team purchases a 1-year certificate, manually installs it on a load balancer, and leaves the company 8 months later. The renewal email goes to an unmonitored shared inbox. The certificate expires, terminating all inbound traffic.
A server provides the leaf certificate but fails to provide the intermediate certificates required to build a path to the Root CA. Browsers with cached intermediates might succeed, while CLI tools and APIs hard-fail.
When facing a suspected TLS issue, you cannot rely on browser padlocks. You must use tools that show you the raw handshake parameters. The definitive tool is openssl:
echo | openssl s_client -showcerts -servername yourdomain.com -connect yourdomain.com:443 2>/dev/null | openssl x509 -inform pem -noout -dates
This command initiates a handshake, parses the returned leaf certificate, and outputs the exact 'notBefore' and 'notAfter' timestamps.
Monitoring certificates by tracking file timestamps on disk is an anti-pattern. What actually matters in production is what the edge proxy is serving to the world.
A mature monitoring posture requires synthetic probes that frequently connect to your public endpoints, negotiate TLS, and assert that the expiration date is greater than a safe threshold (e.g., 30 days). If the threshold is breached, it creates an incident ticket with ample time for humans to intervene.
The key to TLS reliability is removing assumptions about automated scripts and verifying the actual cryptographic output. By deploying Heimdall Observer, teams can continuously audit all public endpoints, instantly catching misconfigured chains, expiring certificates, and invalid SANs globally before they manifest as customer-facing downtime.
Join thousands of teams who rely on Heimdall to keep their websites and APIs online 24/7. Get started with our free plan today.
Start monitoring for free
Senior Systems Reliability Engineer focused on uptime, incident response, and building monitoring systems that surface problems before users notice.


