Las fallas de DNS a menudo son invisibles para los sistemas de monitoreo internos. Aprenda cómo las cadenas de resolución recursiva y la latencia pueden derribar su infraestructura.

Si ha estado de guardia el tiempo suficiente, conoce la sensación. Las alertas de PagerDuty se encienden, los paneles se ponen rojos y los clientes inundan los canales de soporte. Su base de datos está saludable. Sus servidores de aplicaciones están zumbando. Los balanceadores de carga informan cero conexiones caídas.
Entonces, ¿qué está caído exactamente?
A menudo, no es su infraestructura en absoluto. Es el tejido conectivo que lleva el tráfico a su puerta de entrada: el DNS. Todo parece saludable hasta que el tráfico desaparece. Las fallas de DNS rara vez son obvias porque residen en las capas entre su usuario y su borde. Analicemos por qué sucede esto y cómo verificar su pila de afuera hacia adentro.
La mayoría de las configuraciones de monitoreo sufren de „ceguera de adentro hacia afuera“. Sus servicios internos se hacen ping entre sí usando direcciones IP privadas o resolución local de VPC. Informan un 100% de tiempo de actividad porque, dentro del jardín amurallado de su proveedor de nube, pueden comunicarse perfectamente.
Pero desde la perspectiva de su usuario, navegar a su sitio es un viaje de múltiples pasos a través de la guía telefónica del internet público. Si esa resolución falla, su panel de métricas internas se mantendrá verde felizmente mientras sus ingresos llegan a cero.
Para comprender por qué falla el DNS, debe comprender cómo se resuelve. Cuando un usuario escribe su URL, su dispositivo no simplemente „sabe“ su IP. Comienza un viaje recursivo por todo el mundo:
El sistema operativo del cliente pregunta al DNS configurado (generalmente un ISP o 1.1.1.1). Esta es la „Primera Milla“ del DNS.
El resolutor del ISP verifica su caché. Si está vacío, consulta los Servidores de Nombres Raíz para la ubicación del TLD.
La raíz apunta al resolutor hacia los servidores de nombres .com o .io. Estos se administran a nivel de registro.
Finalmente, la solicitud llega a su proveedor de DNS (por ejemplo, Route53, Cloudflare). Solo entonces se devuelve el registro IP final al usuario.
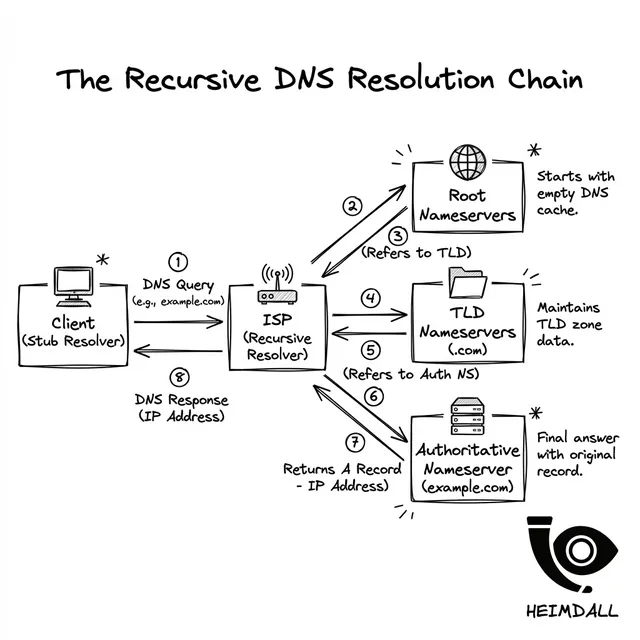
Cada uno de estos saltos es un punto de falla potencial. Si sus servidores autoritativos están dejando caer paquetes, el resolutor recursivo podría agotar el tiempo de espera y devolver un SERVFAIL. Peor aún, si un servidor TLD tiene datos obsoletos, su tráfico se envía al vacío.
El tiempo de inactividad rara vez es causado por una sola falla. En DNS, a menudo es una secuencia en cascada de eventos:
| Modo de falla | Síntoma | Método de detección |
|---|---|---|
| Parálisis de TTL | Arreglos tardan 24h+ | Monitoreo de Número de Serie |
| Deriva de Registro | IPs incorrectas en regiones | Chequeos Autoritativos Globales |
| Interrupción de TLD | SERVFAIL total global | Validación Recursiva Sintética |
En 2016, un ataque DDoS masivo contra Dyn DNS (un proveedor autoritativo) derribó Twitter, Netflix y GitHub. El ataque no se dirigió a las empresas; se dirigió a los servidores de nombres del proveedor de DNS. ¿El resultado? Los resolutores recursivos de todo el mundo no pudieron encontrar la fuente autoritativa, lo que provocó una cascada masiva de SERVFAIL.
Cuando sospeche un problema de DNS, deje de usar su navegador. Debe hablar directamente con las fuentes autoritativas. Aquí está la ruta de diagnóstico estándar:
Use dig para consultar sus servidores de nombres directamente. Esto omite cualquier almacenamiento en caché del ISP:
dig @ns1.your-dns-provider.com yourdomain.com A
Use dig +trace para ver exactamente dónde se rompe la cadena:
dig yourdomain.com +trace
Una práctica madura de SRE requiere monitorear señales de DNS específicas. Valide la latencia p99 y las tasas de error desde múltiples puntos de vista globales:
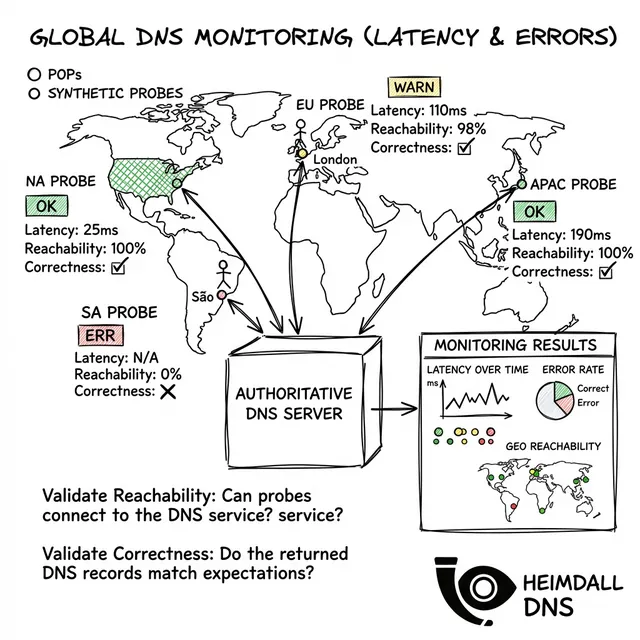
El DNS es aburrido hasta que rompe su empresa. Herramientas como Heimdall Observer existen para detectar estos modos de falla antes de que afecten a los usuarios.
Heimdall Observer fue construido para proteger su infraestructura digital. Comience hoy con alertas en tiempo real, análisis detallados y monitoreo confiable.
Comienza Gratis
Ingeniero de infraestructura enfocado en DNS, redes y las capas invisibles que determinan si las aplicaciones son accesibles.
