大企業がなぜ未だに証明書の更新漏れで壊滅的な障害を起こすのか、その技術的要因と監視の盲点を分析します。

これは、エンジニアリングチームが直面しうる最も恥ずかしい障害です。Kubernetes、分散データベース、グローバルCDNを駆使しているにもかかわらず、わずか10ドルのTLS証明書の更新を忘れたために、数百万ドル規模のアーキテクチャ全体が突然停止してしまうのです。
実際には、組織が「自動化されているから大丈夫」と過信したり、外部の文脈(コンテキスト)が欠落した監視システムに依存している場合にこの失敗が起こります。
大規模なインシデント(Epic Games、Spotify、Microsoftなど)において、根本原因が一般向けの公開ウェブサイトであることは稀です。多くの場合、放置された内部APIゲートウェイ、レガシーなアイデンティティプロバイダー、またはマシン間(M2M)認証エンドポイントから発生します。
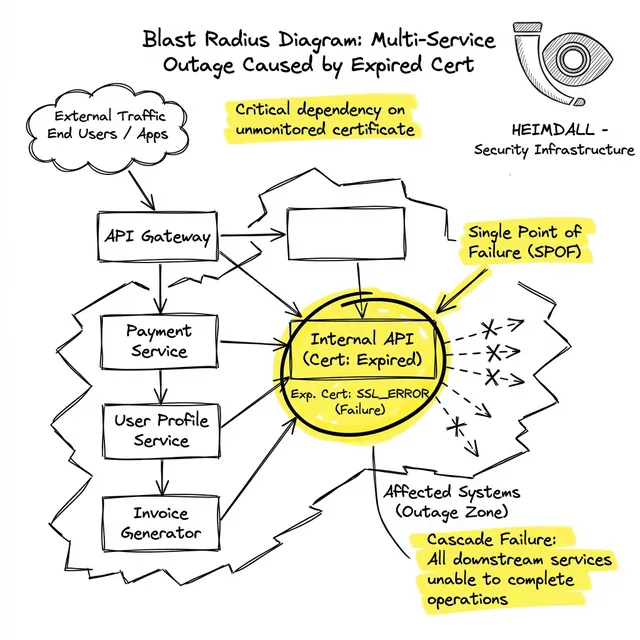
認証APIの証明書が期限切れになると、フロントエンドのWebサーバーが認証に失敗し、500エラーを返します。バックエンドがエラーを返したため、ロードバランサーはWebサーバーをローテーションから外します。システム全体が連鎖的に障害に陥り、オンコールエンジニアには「証明書の期限切れ」ではなく「5xxエラー率の上昇」としてアラートが飛びます。
なぜ証明書は見逃されるのでしょうか?多くの場合、認証局(CA)は30日前、15日前、3日前に警告メールを送信しています。しかし以下の理由が考えられます:
このようなポストモーテム(事後分析)を回避するため、SREチームは「信頼せよ、されど検証せよ」という姿勢をとる必要があります。証明書を発行するシステム自体に、その監視まで依存してはいけません。
外部の客観的な「単一の真実(Source of Truth)」を導入することは不可欠です。Heimdall Observerは、この独立した監査役として機能します。内部のCI/CDパイプラインから監視を切り離すことで、Heimdallは実際の暗号化状態に基づいた明確なアラートを提供し、期限切れ証明書が再びインフラを麻痺させることを防ぎます。

可用性、インシデント対応、そしてユーザーが気づく前に問題を表面化させるモニタリングシステムの構築に焦点を当てた、シニアシステム信頼性エンジニア(SRE)。

