Why DNS is the Silent Killer of High Uptime
DNS failures are often invisible to internal monitoring systems. Learn how recursive resolution chains and TLD latency can silently take down your infrastructure.

How DNS Failures Cause Invisible Downtime
If you've been on call long enough, you know the feeling. The PagerDuty alerts light up, dashboards turn red, and customers are flooding support channels. Your database is healthy. Your application servers are humming. The load balancers report zero dropped connections.
So what is actually down?
Often, it's not your infrastructure at all. It's the connective tissue that gets traffic to your front door: DNS. Everything looks healthy until traffic disappears. DNS failures are rarely obvious because they reside in the layers between your user and your edge. Let's break down why this happens and how to verify your stack from the outside-in.
The Illusion of Local Uptime
Most monitoring setups suffer from "inside-out blindness." Your internal services ping each other using private IP addresses or VPC-local resolution. They report 100% uptime because, inside your cloud provider's walled garden, they can communicate perfectly.
But from your user's perspective, navigating to your site is a multi-step journey through the public internet's phonebook. If that resolution fails, your internal metrics dashboard will happily stay green while your revenue hits zero.
Technical Deep Dive: The Recursive DNS Resolution Chain
To understand why DNS fails, you have to understand how it resolves. When a user types your URL, their device doesn't just "know" your IP. It starts a recursive journey across the globe:
1. The Stub Resolver
The client OS asks the configured DNS (usually an ISP or 1.1.1.1). This is the "First Mile" of DNS.
2. The Recursive Resolver
The ISP resolver checks its cache. If empty, it queries the Root Nameservers for the TLD location.
3. The TLD Nameservers
The root points the resolver to the .com or .io nameservers. These are managed at the registry level.
4. The Authoritative Nameserver
Finally, the request reaches your DNS provider (e.g., Route53, Cloudflare). Only then is the final IP record returned to the user.
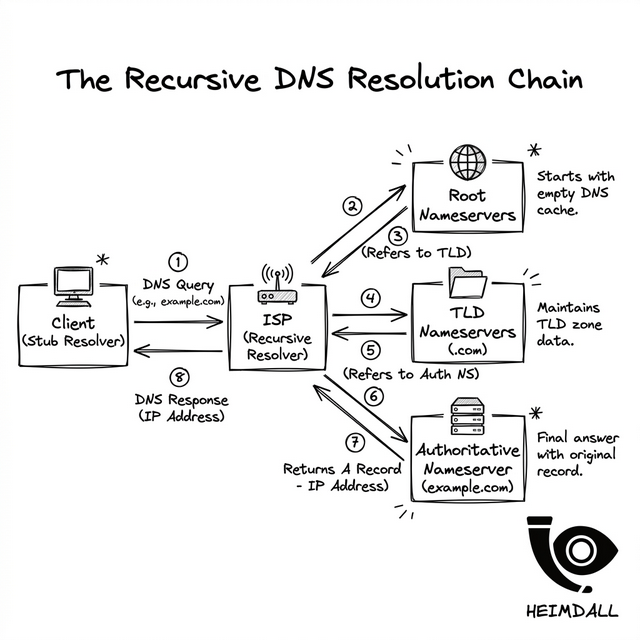
Every one of these jumps is a potential failure point. If your authoritative servers are dropping packets, the recursive resolver might time out and return a SERVFAIL. Worse, if a TLD server has stale data, your traffic is sent to a void.
Common DNS Failure Modes in Production
Downtime is rarely caused by a single failure. In DNS, it's often a cascading sequence of events:
| Failure Mode | Symptom | Detection Method |
|---|---|---|
| TTL Paralysis | Fixes take 24h+ to propagate | Serial Number Monitoring |
| Record Drift | Wrong IPs returned in some regions | Global Authoritative Checks |
| TLD Outage | Total SERVFAIL globally | Synthetic Recursive Validation |
The 2016 Dyn DDoS Incident
In 2016, a massive DDoS attack against Dyn DNS (an authoritative provider) took down Twitter, Netflix, and GitHub. The attack didn't target the companies; it targeted the DNS provider's nameservers. The result? Recursive resolvers globally could not find the authoritative source, leading to massive SERVFAIL cascading through the .com and .net namespaces.
How to Debug DNS Resolution Problems
When you suspect a DNS issue, stop using your browser. You need to talk directly to the authoritative sources. Here is the standard diagnostic path:
Check the Authoritative Response
Use dig to query your nameservers directly. This bypasses any ISP caching that might be lying to you:
dig @ns1.your-dns-provider.com yourdomain.com A
Isolate the Bottleneck with Trace
If resolution is slow or failing, use dig +trace to see exactly where the resolution chain breaks:
dig yourdomain.com +trace
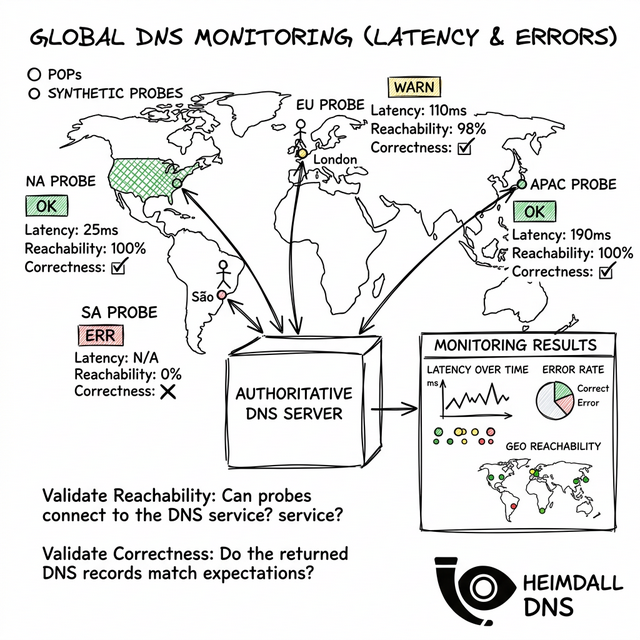
How to Monitor DNS Resolution Latency and Errors
A mature SRE practice requires monitoring specific DNS signals. You shouldn't just check if a domain resolves; you should validate the p99 latency and error rates from multiple global vantage points:
- Resolution Latency (P99): Higher latency in specific regions indicates routing issues or overcapacity nameservers.
- SERVFAIL Rates: Sudden spikes in SERVFAIL often signal a DDoS on your upstream provider.
- NXDOMAIN Drift: Detects unauthorized changes or "poisoning" where your domain suddenly stops resolving.
Hardening Your DNS Infrastructure
- Treat DNS infrastructure with the same rigor as your primary database.
- Implement Multi-Provider DNS where possible to avoid single points of failure.
- Monitor your authoritative nameservers directly from global regions.
Conclusion
DNS is boring until it breaks your company. Tools like Heimdall Observer exist to detect exactly these failure modes—like record drift, hijacking, and latency spikes—before they impact your end users. By query-checking your authoritative servers from multiple geographic points, you ensure that the internet's phonebook is always pointing the world to your front door.
DNS、ネットワーク、そしてアプリケーションが到達可能かどうかを決定する見えない層に焦点を当てたインフラストラクチャエンジニア。
"本記事のような事象を監視するために Heimdall Observer を構築しました。"