Configurar um DNS TTL muito alto pode causar quedas de 24 horas, enquanto configurá-lo muito baixo pode sobrecarregar seus servidores. Aprenda boas práticas.

O Time-To-Live (TTL) é o motor do cache na internet. É um inteiro único que dita o equilíbrio entre agilidade e resiliência. Configure-o muito alto, e uma migração simples se torna uma saga de vários dias. Configure-o muito baixo, e você corre o risco de sobrecarregar seu provedor DNS.
Quando você publica um registro A com um TTL de 3600 segundos, está dizendo a cada ISP no mundo: 'Não me pergunte por este registro novamente por uma hora.' Isso fornece resiliência massiva. Se o seu provedor DNS sofrer uma queda total 5 minutos depois, seus usuários não notarão, porque seus ISPs já têm a resposta.
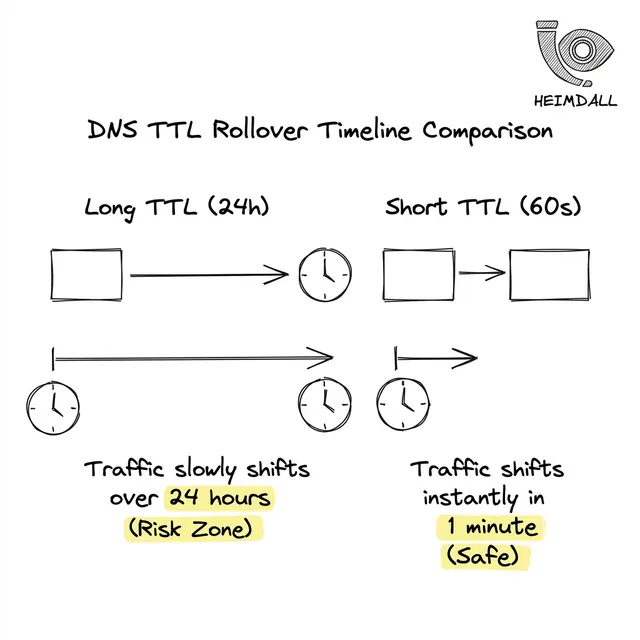
Mas a resiliência contrasta com a agilidade. Se o seu balanceador de carga principal falhar e você atualizar seu DNS para apontar para um backup, esse TTL de 1 hora significa que o tráfego continuará fluindo para o balanceador morto até que os caches locais expirem.
Um equívoco comum é que você controla seu TTL globalmente. Na realidade, grandes resolvers recursivos (como algumas operadoras móveis) imporão seus próprios TTLs mínimos para economizar banda. Mais importante, CDNs frequentemente anulam seu TTL autoritativo inteiramente para registros proxied.
Operar DNS em produção exige uma abordagem escalonada para os TTLs:
O gerenciamento de TTL é a base do roteamento sem downtime.
Com o Heimdall Observer, você pode auditar o TTL de seus registros críticos para garantir que eles não foram acidentalmente fixados em um valor alto, prevenindo um lockout catastrófico durante seu próximo incidente.
Junte-se a milhares de equipes que confiam no Heimdall para manter seus sites e APIs online 24/7. Comece com nosso plano gratuito hoje.
Comece a monitorar gratuitamente
Engenheiro de Confiabilidade de Sistemas (SRE) Sênior focado em disponibilidade, resposta a incidentes e construção de sistemas de monitoramento que antecipam problemas antes que os usuários percebam.


