Pare de confiar em métricas internas para quedas externas. Aprenda os princípios da arquitetura fora-para-dentro.

Ao avaliar plataformas de observabilidade, as equipes de engenharia costumam priorizar o rastreamento APM, agregação de logs e cardinalidade de métricas internas. Mas se você confiar nessas ferramentas para monitorar o DNS, estará configurando-as para mentir para você.
Um agente Datadog rodando em uma instância EC2 opera dentro de uma VPC altamente privilegiada. Quando ele faz ping em um endpoint de API, usa um resolver DNS privado da nuvem. Como essa rede interna ignora completamente a internet pública, seu agente reportará 100% de uptime enquanto os servidores de nomes públicos reais estão offline.
Para monitorar dependências externas, suas ferramentas devem viver fora da sua borda de confiança.
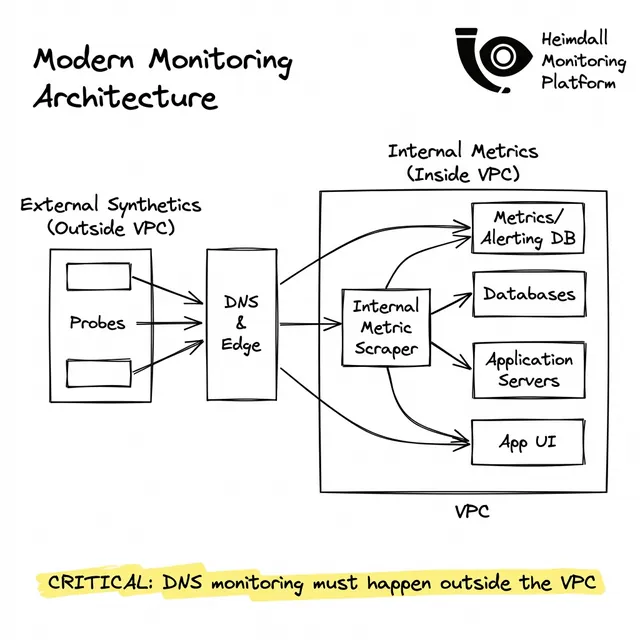
Uma ferramenta dedicada de monitoramento de DNS deve fornecer testes 'Sintéticos': implantando ambientes de execução sem estado (sondas) leves em múltiplos provedores globais para rodar consultas DNS brutas exatamente como um usuário faria.
Uma ferramenta de nível de produção deve rastrear:
Como a internet é barulhenta, uma única sonda sintética em Frankfurt falhando em resolver seu domínio não constitui um incidente Sev-1; geralmente indica um 'flap' de BGP local. As melhores ferramentas impõem uma 'Regra de Três Regiões': o PagerDuty só dispara se sondas em pelo menos três regiões distintas reportarem falha simultânea.
Confiar em um dashboard de métricas internas durante uma queda de DNS é como confiar no marcador de combustível em um carro sem rodas.
Plataformas nativas para a borda, como o Heimdall Observer, vivem fora do jardim murado das nuvens. Elas proveem o monitoramento monitoramento dedicado para travar falhas públicas antes que estourem.
Junte-se a milhares de equipes que confiam no Heimdall para manter seus sites e APIs online 24/7. Comece com nosso plano gratuito hoje.
Comece a monitorar gratuitamente
Engenheiro de Confiabilidade de Sistemas (SRE) Sênior focado em disponibilidade, resposta a incidentes e construção de sistemas de monitoramento que antecipam problemas antes que os usuários percebam.

