Pare de confiar no cache local. Aprenda fluxos de trabalho e ferramentas de linha de comando que SREs usam para isolar falhas de DNS em cascata.

Quando alertas de incidentes graves disparam e os clientes relatam que seu serviço está inacessível, o instinto é reiniciar pods ou controladores de Ingress. Mas se suas métricas internas estão com sinal verde, você provavelmente está enfrentando uma interrupção de roteamento ou de DNS.
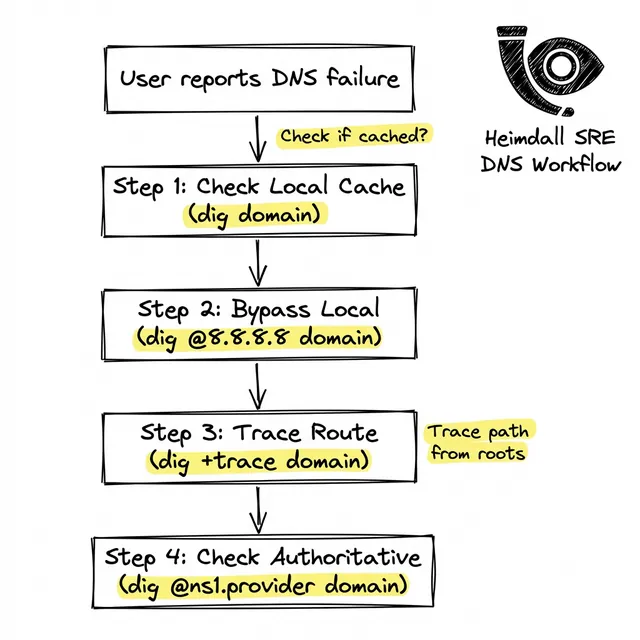
SREs eficazes não adivinham durante uma falha; eles isolam o domínio da falha. Depurar um problema de DNS exige sair da sua infraestrutura e imitar a jornada exata que um pacote faz do dispositivo de um usuário até seus servidores de nomes autoritativos.
O erro mais comum que engenheiros cometem é testar com 'ping' ou em seus navegadores locais. Essas ferramentas perguntam ao resolver stub do sistema operacional para onde ir. Se o SO recebeu recentemente uma resposta negativa (NXDOMAIN) ou um IP desatualizado, ele mentirá para você com confiança até que seu cache expire.
Antes de mergulhar em pacotes DNS brutos, uma técnica altamente eficaz é provar que o backend está saudável ignorando intencionalmente o DNS na camada de aplicação. Você pode usar o curl para forçar uma conexão ao IP saudável conhecido, passando o cabeçalho Host correto:
curl -v --resolve seudominio.com:443:192.0.2.1 https://seudominio.com
Se essa requisição for bem-sucedida e retornar um 200 OK, você provou definitivamente que sua computação, balanceadores de carga e certificados TLS estão completamente saudáveis. O único componente quebrado é a resolução de nomes.
Uma vez que você sabe que o backend está bem, deve rastrear exatamente qual servidor DNS está pisando na bola. Isso exige interrogar a hierarquia da internet.
O resto do mundo vê a queda ou apenas o ISP do seu escritório? Pergunte diretamente a um resolver público:
dig @1.1.1.1 seudominio.com A
Se o Cloudflare ou o Google DNS não conseguirem resolver, use a flag de trace para forçar sua máquina local a agir como um resolver recursivo. Ela começará nos servidores Raiz, irá para o TLD e finalmente consultará seus servidores autoritativos:
dig +trace seudominio.com
Observe a saída com atenção. Se o rastreamento for bem-sucedido até os servidores .com, mas o repasse final para o seu provedor (como AWS Route53) der timeout ou retornar REFUSED, sua zona autoritativa está quebrada.
Executar esses comandos durante um incêndio desperdiça minutos preciosos. Equipes de engenharia maduras utilizam redes de monitoramento sintético global para executar exatamente essas verificações continuamente.
Ao implantar o Heimdall Observer, você automatiza o processo tedioso de executar varreduras globais, recebendo alertas instantâneos no segundo em que um servidor autoritativo para de responder.
Junte-se a milhares de equipes que confiam no Heimdall para manter seus sites e APIs online 24/7. Comece com nosso plano gratuito hoje.
Comece a monitorar gratuitamente
Engenheiro de infraestrutura focado em DNS, redes e nas camadas invisíveis que determinan se as aplicações são alcançáveis.


