Falhas de DNS são pontos cegos enormes para times de SRE. Aprenda os modos de falha, fluxos de depuração e estratégias para prevenir downtime silencioso.

Quando um aplicativo fica offline, as equipes de engenharia correm para seus dashboards de APM. Eles verificam gráficos de CPU, pools de conexão de banco de dados e logs de aplicação. Muitas vezes, não encontram nada de errado. Os servidores estão perfeitamente saudáveis, mas os clientes estão inundando o suporte com mensagens de 'site inacessível'.
Esse fenômeno — frequentemente apelidado de 'cegueira de dentro para fora' — acontece porque seus testes internos não percorrem o mesmo caminho que seus usuários. Eles são completamente cegos para a camada de roteamento mais crítica e mais frágil da internet: o Sistema de Nomes de Domínio (DNS).
Como o DNS opera como um banco de dados massivo, globalmente distribuído e eventualmente consistente, uma falha na cadeia de resolução não registrará um erro '500 Internal Server Error'. Registrará como silêncio absoluto.
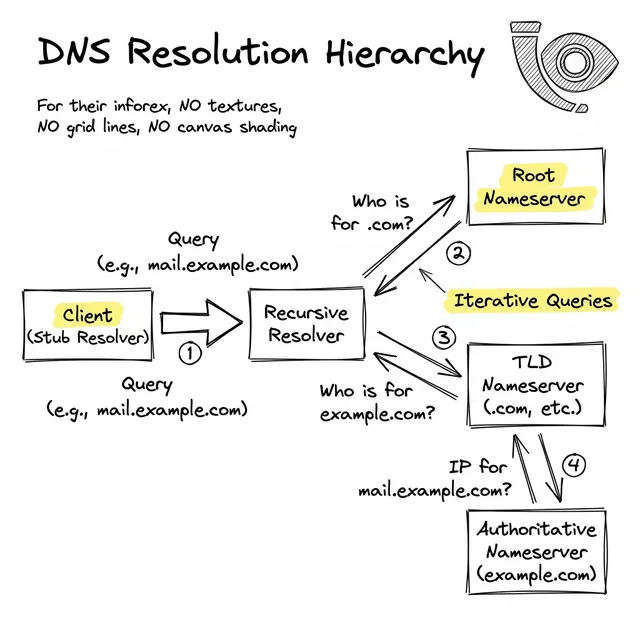
Como ilustrado, a jornada de resolução introduz várias dependências externas antes que um handshake TCP possa sequer começar:
Embora quedas catastróficas no nível da Raiz sejam excepcionalmente raras, as bordas dessa rede falham constantemente. As interrupções mais comuns surgem de configurações incorretas ou timeouts em cascata:
Durante uma migração rápida de infraestrutura, se seus endereços IP anteriores tinham um Time-To-Live (TTL) de 24 horas, a maioria da internet se recusará a consultar seus novos servidores até que esse temporizador expire, deixando seus usuários isolados em hardware offline.
Se você opera vários servidores de nomes autoritativos redundantes, uma sincronização de zona incompleta pode causar falhas intermitentes. Um usuário em Tóquio pode receber o IP correto, enquanto um usuário em Londres atinge um servidor que serve uma versão antiga do arquivo de zona.
Ao investigar uma suspeita de queda de DNS, você deve ignorar o cache do navegador e consultar a fonte da verdade. Em vez de um 'dig' padrão, você pode verificar especificamente os números de série em seus servidores para detectar problemas de sincronização split-brain:
host -t SOA seudominio.com ns1.seuprovedor.com host -t SOA seudominio.com ns2.seuprovedor.com
Se os números de série retornados não coincidirem perfeitamente, seus servidores estão fora de sincronia e servindo realidades diferentes para diferentes regiões.
Substituir verificações de uptime baseadas em ping por monitoramento externo abrangente é obrigatório para cargas de trabalho em produção.
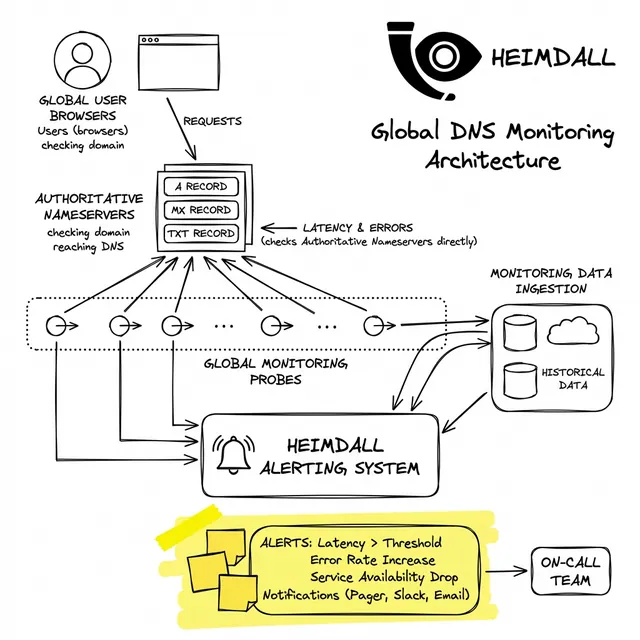
Uma postura robusta exige testar o caminho de resolução de fora para dentro. Suas sondas de monitoramento devem:
Explore nossa série sobre engenharia e escalabilidade da confiabilidade do DNS:
A resiliência operacional não se trata apenas de auto-scaling de computação; trata-se de garantir que seus clientes possam alcançar essa computação de forma confiável. Nós projetamos o
Heimdall Observer para preencher exatamente essa lacuna de visibilidade. Ao consultar seus endpoints autoritativos a partir de uma rede de pontos de vantagem global, o Heimdall fornece alertas em tempo real sobre desvios de latência, picos de SERVFAIL e incompatibilidade de registros antes que virem incidentes.
Junte-se a milhares de equipes que confiam no Heimdall para manter seus sites e APIs online 24/7. Comece com nosso plano gratuito hoje.
Comece a monitorar gratuitamente
Engenheiro de Confiabilidade de Sistemas (SRE) Sênior focado em disponibilidade, resposta a incidentes e construção de sistemas de monitoramento que antecipam problemas antes que os usuários percebam.


