DNS障害はしばしば内部監視システムに見えません。再帰解決チェーンがどのようにインフラを沈黙させるかを学びます。

オブザーバビリティプラットフォームはシステム追跡のために設計されています。しかし、リクエストがインフラのエッジに到達する前に障害が発生したらどうなるでしょうか?ダッシュボードは自信満々に100%稼働を報告しますが、顧客はアクセス不能を経験します。
メトリクスが嘘をつく理由は、クラウドネットワークの分割ホライズンの性質です。内部KubernetesポッドはプライベートVPCリゾルバーを使用して解決します。内部ネットワークは完璧であるため、ヘルスチェックは成功します。
しかし、外部の顧客は、公開Ingressを発見するためにパブリックインターネットの再帰解決チェーンに依存しています。
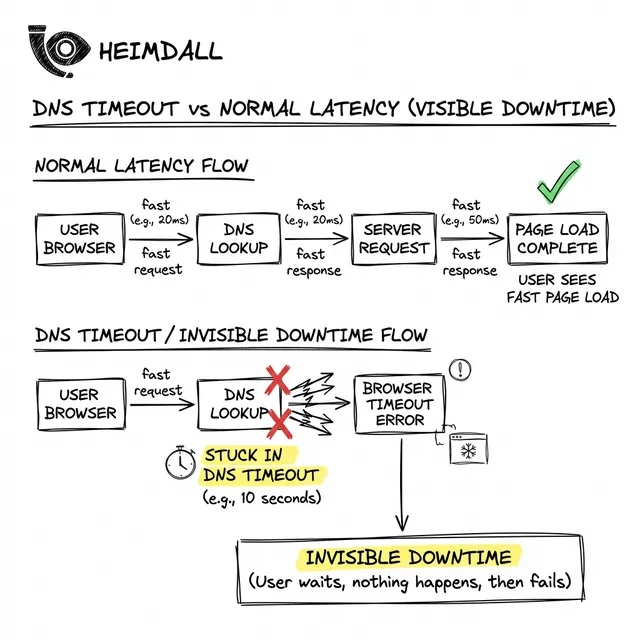
「見えない」障害は、パブリック権威レコードが中断されたときに発生します。2021年のSlack障害はその一例です。設定ミスによりコアAPIのAレコードが誤って削除されました。
内部でSlackサーバーは動作しジョブを処理していましたが、新規クライアントはドメインを解決できなくなりました。インターネットはSlackの場所を忘れたのです。
この差異を証明するためにテストスクリプトを書けます。OSキャッシュを無視して、明示的にDNSでのパブリック権威サーバーへの問い合わせを強制します:
nslookup -debug yourdomain.com ns1.your-dns-provider.com
このコマンドがタイムアウトする場合、内部ツールのアラートに関係なく権威層の障害です。
信頼性を設計する際、外部の到達可能性検証のために内部ヘルスチェックだけに依存してはいけません。

DNS、ネットワーク、そしてアプリケーションが到達可能かどうかを決定する見えない層に焦点を当てたインフラストラクチャエンジニア。


