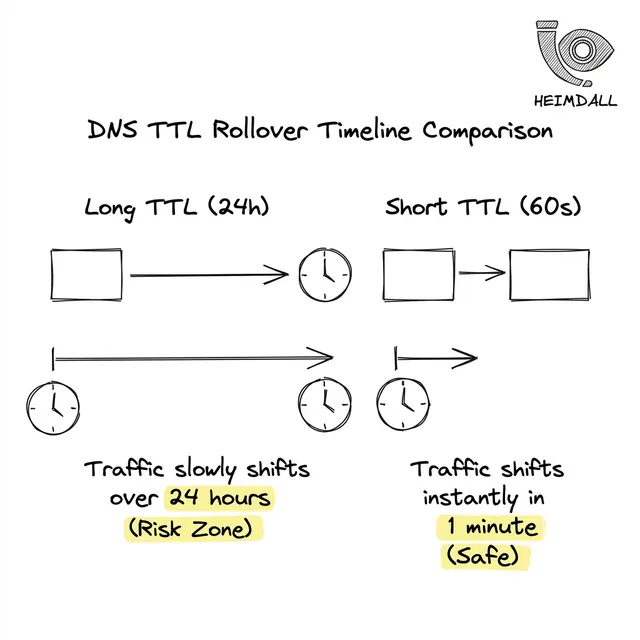
TTLが高すぎると24時間の障害に繋がります。低すぎるとサーバーに負荷がかかります。本番管理のベストプラクティスを学びます。

Time-To-Live(TTL)はインターネットキャッシュのエンジンです。高すぎると移行が苦痛になり、低すぎるとDNSプロバイダーに負荷がかかります。
高いTTLはサーバー障害時のレジリエンスを提供しますが、インシデント時の切り替え速度を低下させます。

SERVFAILは解決チェーンが壊れていることを意味します。トラフィックを回復するために、DNSSEC検証失敗や不完全な委任を修正する方法を学びます。

外部の障害に対して内部のメトリクスを信頼しないでください。SREチーム向けの「外部から内部(Outside-In)」のDNS監視原則を学びます。

DNSレイテンシはアプリがリクエストを記録する前に発生します。Anycastルーティングの失敗と、エッジからの真のP99測定方法を学びます。

可用性、インシデント対応、そしてユーザーが気づく前に問題を表面化させるモニタリングシステムの構築に焦点を当てた、シニアシステム信頼性エンジニア(SRE)。