DNSレイテンシはアプリがリクエストを記録する前に発生します。Anycastルーティングの失敗と、エッジからの真のP99測定方法を学びます。

エンジニアリングチームは、Time-To-First-Byte(TTFB)を50ミリ秒削るために膨大なリソースを投入します。しかし、彼らはしばしば最初のステップであるホスト名の解決を無視しています。
現代のDNSはAnycastルーティングで動いています。通常は素晴らしいですが、BGPは距離ではなくネットワークのホップ数でルーティングします。リンクが切れると遅延が爆発します。
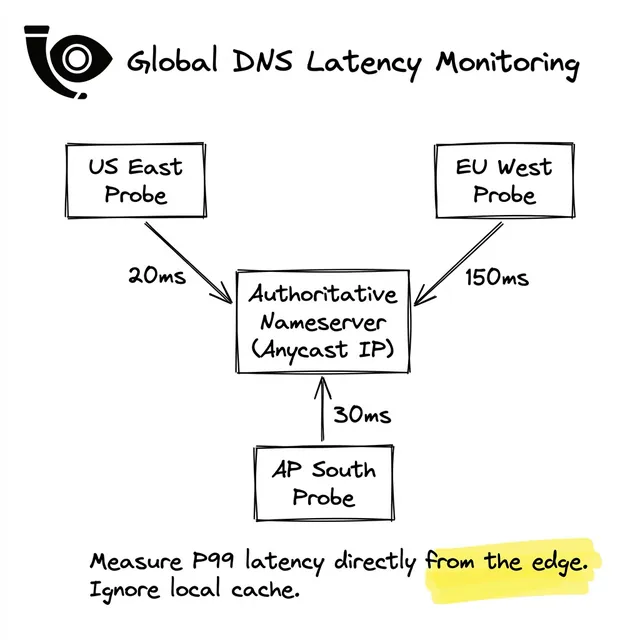
DNSレイテンシはHTTP接続の前に発生するため、バックエンドログには決して現れません。外部から継続的に(合成/シンセティック)測定するしかありません。

SERVFAILは解決チェーンが壊れていることを意味します。トラフィックを回復するために、DNSSEC検証失敗や不完全な委任を修正する方法を学びます。

外部の障害に対して内部のメトリクスを信頼しないでください。SREチーム向けの「外部から内部(Outside-In)」のDNS監視原則を学びます。
DNSレイテンシはアプリがリクエストを記録する前に発生します。Anycastルーティングの失敗と、エッジからの真のP99測定方法を学びます。

可用性、インシデント対応、そしてユーザーが気づく前に問題を表面化させるモニタリングシステムの構築に焦点を当てた、シニアシステム信頼性エンジニア(SRE)。