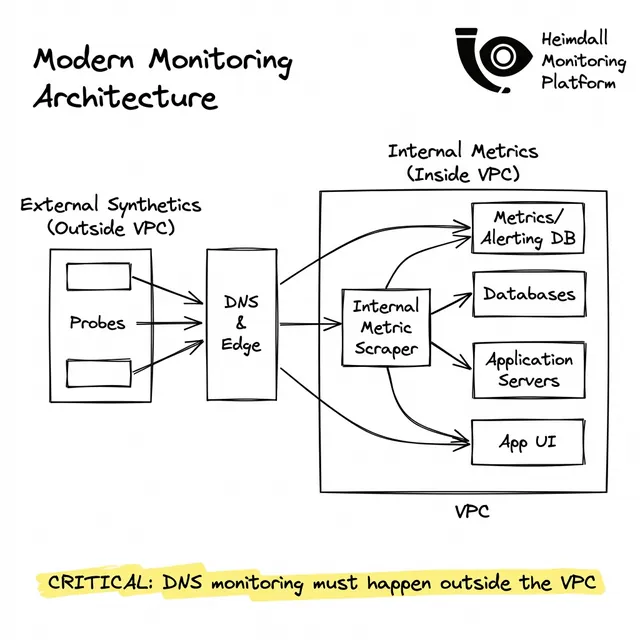
外部の障害に対して内部のメトリクスを信頼しないでください。SREチーム向けの「外部から内部(Outside-In)」のDNS監視原則を学びます。

EC2上のDatadogエージェントは、プライベートなクラウドリゾルバーを利用します。パブリックDNSが落ちていても「100%稼働」と報告します。ツールは信頼境界の「外側」にある必要があります。
優れたツールは「3地域ルール」を適用します。少なくとも3つの異なる地理的地域のプローブが同時に障害を報告した場合にのみ、PagerDuty(アラート)を発火させます。

SERVFAILは解決チェーンが壊れていることを意味します。トラフィックを回復するために、DNSSEC検証失敗や不完全な委任を修正する方法を学びます。
外部の障害に対して内部のメトリクスを信頼しないでください。SREチーム向けの「外部から内部(Outside-In)」のDNS監視原則を学びます。

DNSレイテンシはアプリがリクエストを記録する前に発生します。Anycastルーティングの失敗と、エッジからの真のP99測定方法を学びます。

可用性、インシデント対応、そしてユーザーが気づく前に問題を表面化させるモニタリングシステムの構築に焦点を当てた、シニアシステム信頼性エンジニア(SRE)。