Un análisis técnico de cómo las grandes empresas sufren interrupciones devastadoras debido a renovaciones de certificados omitidas.

Es la interrupción más vergonzosa que puede enfrentar un equipo de ingeniería. A pesar de utilizar Kubernetes, bases de datos distribuidas y CDN globales, toda la arquitectura de millones de dólares se detiene abruptamente porque no se renovó un certificado TLS de $10.
En la práctica, esto suele fallar porque las organizaciones asumen que la automatización es infalible o dependen de sistemas de monitoreo que carecen de contexto externo.
En incidentes importantes (como los experimentados por Epic Games, Spotify y Microsoft), la causa raíz rara vez es el sitio web de cara al público. La interrupción suele tener su origen en una puerta de enlace de API interna descuidada gateway, un proveedor de identidad heredado o un punto final de autenticación de máquina a máquina.
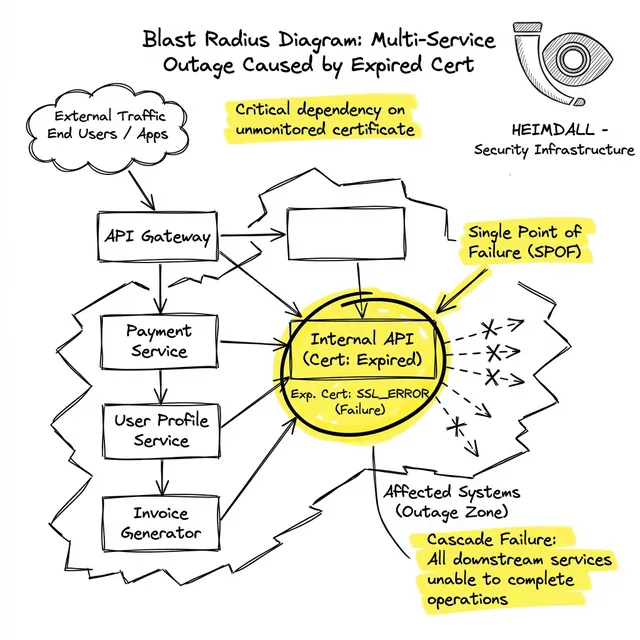
Cuando el certificado en la API de identidad expira, los servidores web frontend no se autentican y lanzan errores 500. Debido a que el backend arrojó un error, los balanceadores de carga sacan los servidores web de la rotación. Todo el sistema cae en cascada y el ingeniero de guardia recibe una alerta de 'Alta tasa de errores 5xx', no de 'Certificado expirado'.
¿Por qué se omiten estos certificados? A menudo, la CA envía correos electrónicos de advertencia con 30, 15 y 3 días de anticipación. Sin embargo:
Para evitar estos postmortems, los equipos de SRE deben adoptar una postura de 'confiar pero verificar'. Nunca confíe en el sistema que genera el certificado para monitorear el certificado.
Implementar una fuente de verdad externa y objetiva no es negociable. Heimdall Observer actúa como este auditor independiente, lo que garantiza que un certificado expirado nunca vuelva a paralizar su infraestructura.
Heimdall Observer fue construido para proteger su infraestructura digital. Comience hoy con alertas en tiempo real, análisis detallados y monitoreo confiable.
Comienza Gratis
Ingeniero sénior de confiabilidad de sistemas (SRE) enfocado en la disponibilidad, respuesta a incidentes y construcción de sistemas de monitoreo que revelen problemas antes de que los usuarios lo noten.

