DNSの障害は内部の監視システムからは見えないことがよくあります。再帰的な解決チェーンとTLDの遅延が、インフラを静かにダウンさせる仕組みを学びます。

オンコールを長く経験している人なら、その感覚がわかるでしょう。PagerDutyのアラートが点灯し、ダッシュボードが赤くなり、カスタマサポートに連絡が殺到します。データベースは正常です。アプリケーションサーバーも稼働しています。ロードバランサーは切断がゼロだと報告しています。
では、いったい何がダウンしているのでしょうか?
多くの場合、それはあなたのインフラそのものではありません。トラフィックを玄関口まで届ける結合組織、つまりDNSです。 トラフィックが消えるまで、すべてが正常に見える。DNS障害が明らかになることは稀です。ユーザーとエッジの間のレイヤーに存在するからです。なぜこれが発生するのか、そしてスタックを外部から内部へどう検証するかを解き明かしましょう。
ほとんどの監視設定は「インサイドアウトの盲目」に陥っています。内部サービスは、プライベートIPまたはVPCローカルの解決を使用して互いに通信します。彼らは100%の稼働率を報告します。クラウドプロバイダーの壁に囲まれた庭の中では完璧に通信できるからです。
しかし、ユーザーから見れば、サイトへの移動はパブリックインターネットの電話帳を通る複数ステップの旅です。この解決に失敗すると、内部メトリックダッシュボードは幸せそうに緑色のままで、収益はゼロになります。
DNSが失敗する理由を理解するには、それがどう解決されるかを理解する必要があります。ユーザーがURLを入力したとき、デバイスがサーバーのIPを「ただ知っている」わけではありません。地球を巡る再帰的な旅が始まります:
クライアントのOSが、設定されたDNS(通常はISPまたは1.1.1.1)に問い合わせます。これがDNSの「ファーストマイル」です。
ISPのリゾルバーがキャッシュを確認します。空の場合、ルートネームサーバー にTLDの場所を問い合わせます。
ルートは、リゾルバーを.comまたは.ioのネームサーバーに向けます。これらはレジストリレベルで管理されます。
最後に、リクエストがDNSプロバイダー(Route53、Cloudflareなど)に到達します。このとき初めて、最終的なIPレコードがユーザーに返されます。
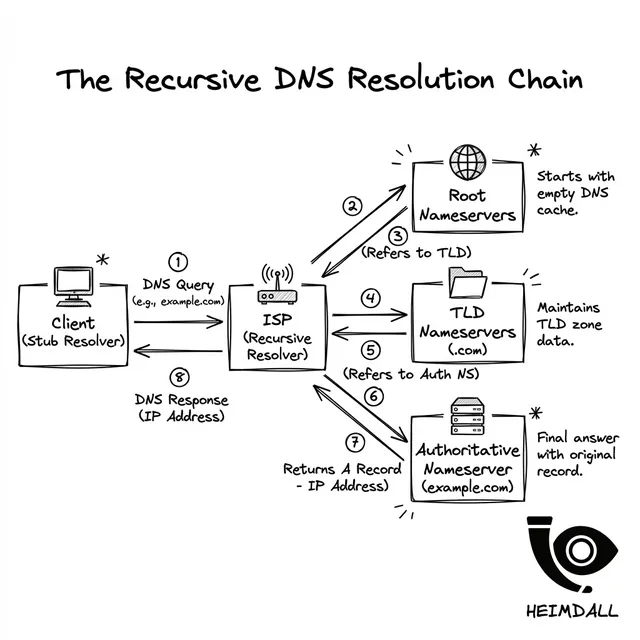
これらジャンプのすべてが潜在的な障害ポイントです。権威サーバーがパケットをドロップしていると、再帰的リゾルバーがタイムアウトし、SERVFAIL を返す可能性があります。さらに悪いことに、TLDサーバーに古いデータがあると、トラフィックが宙に浮きます。
ダウンタイムは単一の障害によって引き起こされることは稀です。DNSでは、連鎖的なイベントのシーケンスであることがよくあります:
| 障害モード | 症状 | 検出方法 |
|---|---|---|
| TTLの麻痺 | 修正の反映に24時間以上かかる | シリアルナンバー監視 |
| レコードのドリフト | 一部地域で誤ったIPが返される | グローバルな権威チェック |
| TLD障害 | グローバルな全面SERVFAIL | 合成再帰的検証 |
2016年、Dyn DNS(権威プロバイダー)に対する大規模なDDoS攻撃がTwitter、Netflix、GitHubをダウンさせました。この攻撃は企業を標的にしたのではなく、DNSプロバイダーのネームサーバーを標的にしました。結果? 世界中の再帰的リゾルバーが権威ソースを見つけられず、大規模なSERVFAILの連鎖を引き起こしました。
DNSの問題が疑われる場合は、ブラウザーの使用を中止してください。権威ソースに直接話しかける必要があります。標準的な診断パスは次のとおりです:
直接問い合わせるために dig を使用します。これにより、ISPのキャッシュが回避されます:
dig @ns1.your-dns-provider.com yourdomain.com A
解決が遅い、または失敗している場合は dig +trace を使用して、解決チェーンのどこで切断されているかを正確に確認します:
dig yourdomain.com +trace
成熟したSREプラクティスには、特定のDNSシグナルの監視が必要です。複数のグローバルな視点から p99の遅延 と エラー率 を検証します:
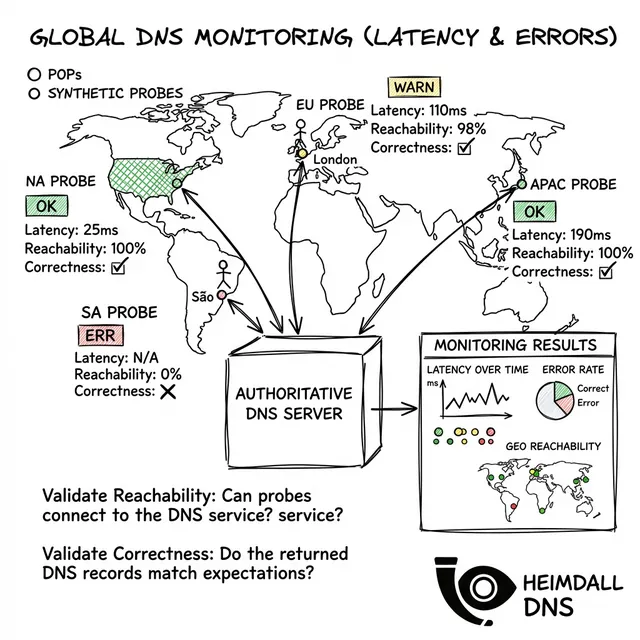
DNSは退屈ですが、会社を破壊するまでは。Heimdall Observerのようなツールは、これらのモードをエンドユーザーに影響を与える前に検知するために存在します。

DNS、ネットワーク、そしてアプリケーションが到達可能かどうかを決定する見えない層に焦点を当てたインフラストラクチャエンジニア。
